Details
-
Improvement
-
Resolution: Unresolved
-
 Major
Major
-
None
-
Enterprise Edition
-
None
Description
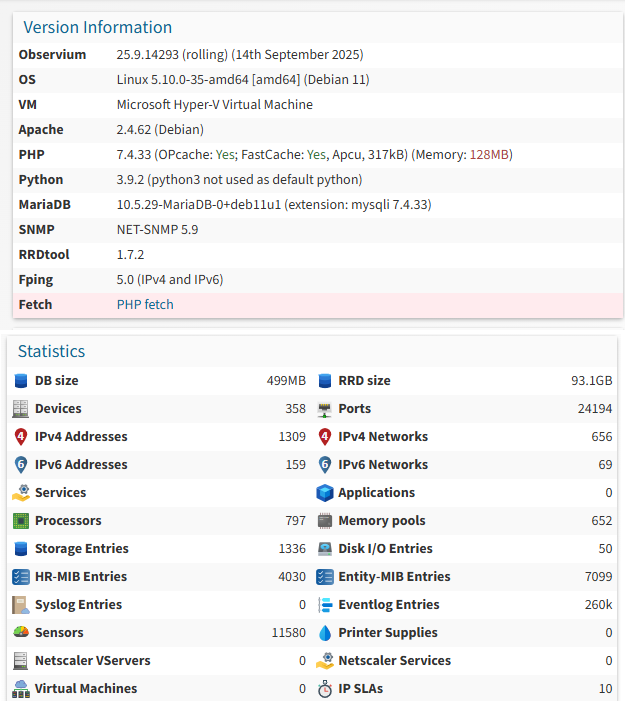
We use observium enterprise 25.9.14293 . Observium is installed on a Virtual machine.
CPU is :
# lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianAddress sizes: 46 bits physical, 48 bits virtualCPU(s): 6On-line CPU(s) list: 0-5Thread(s) per core: 1Core(s) per socket: 6Socket(s): 1NUMA node(s): 1Vendor ID: GenuineIntelCPU family: 6Model: 85Model name: Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHzStepping: 4CPU MHz: 3392.030BogoMIPS: 6784.06Hypervisor vendor: MicrosoftVirtualization type: fullL1d cache: 192 KiBL1i cache: 192 KiBL2 cache: 6 MiBL3 cache: 115.5 MiB
Memory :
#free -tmh total used free shared buff/cache availableMem: 15Gi 3.5Gi 891Mi 653Mi 11Gi 11GiSwap: 0B 0B 0BTotal: 15Gi 3.5Gi 891Mi
We would like to optimize it to speed up page loading, especially on weekends when it is slow.
We have ~23,000 ports and 358 devices.
I have several questions:
- What is a large installation? I often read this term, but I don't know how to measure or define it.
- How can we speed up the loading time of pages and graphs?
- We have enabled "opcode caching."
- We already enabled "fast userspace caching."
- Disable MySQL binary logging done
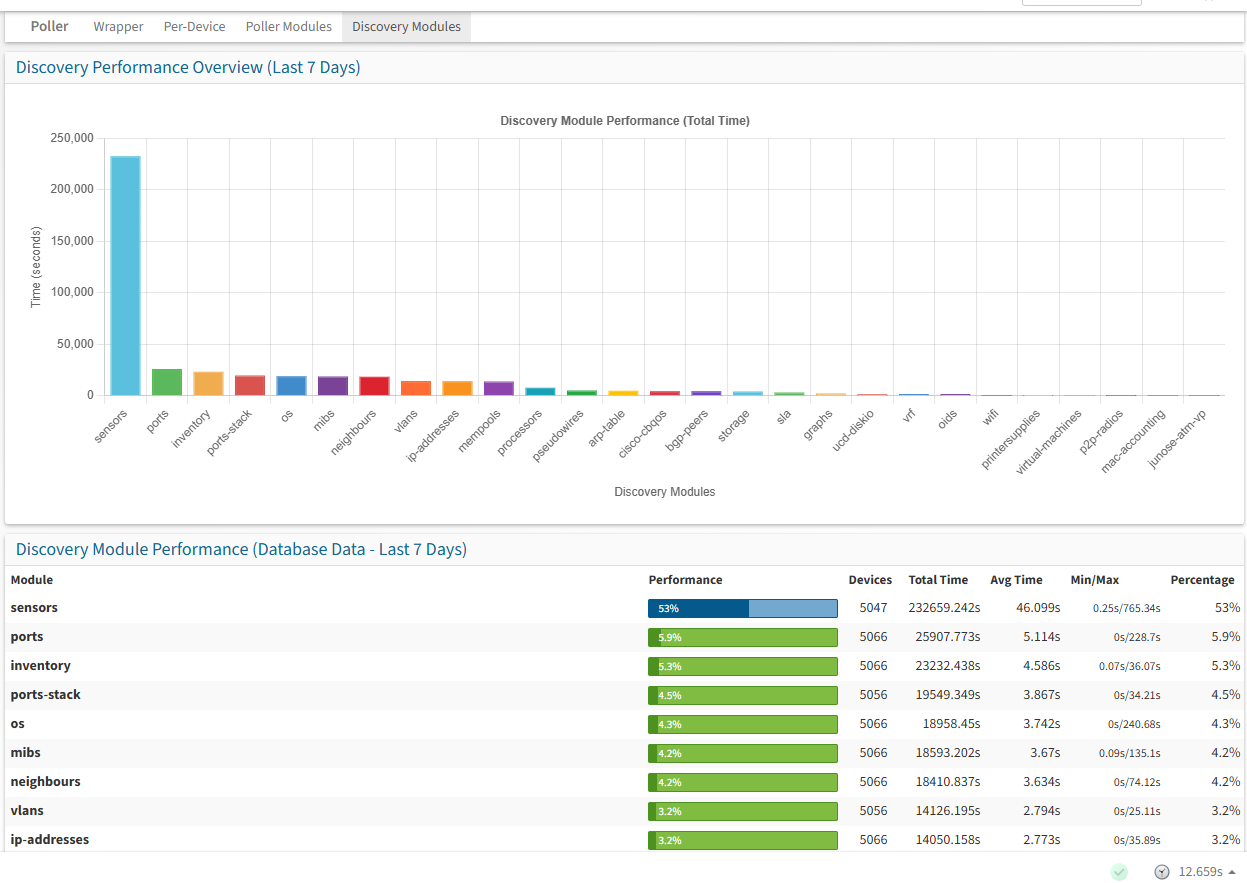
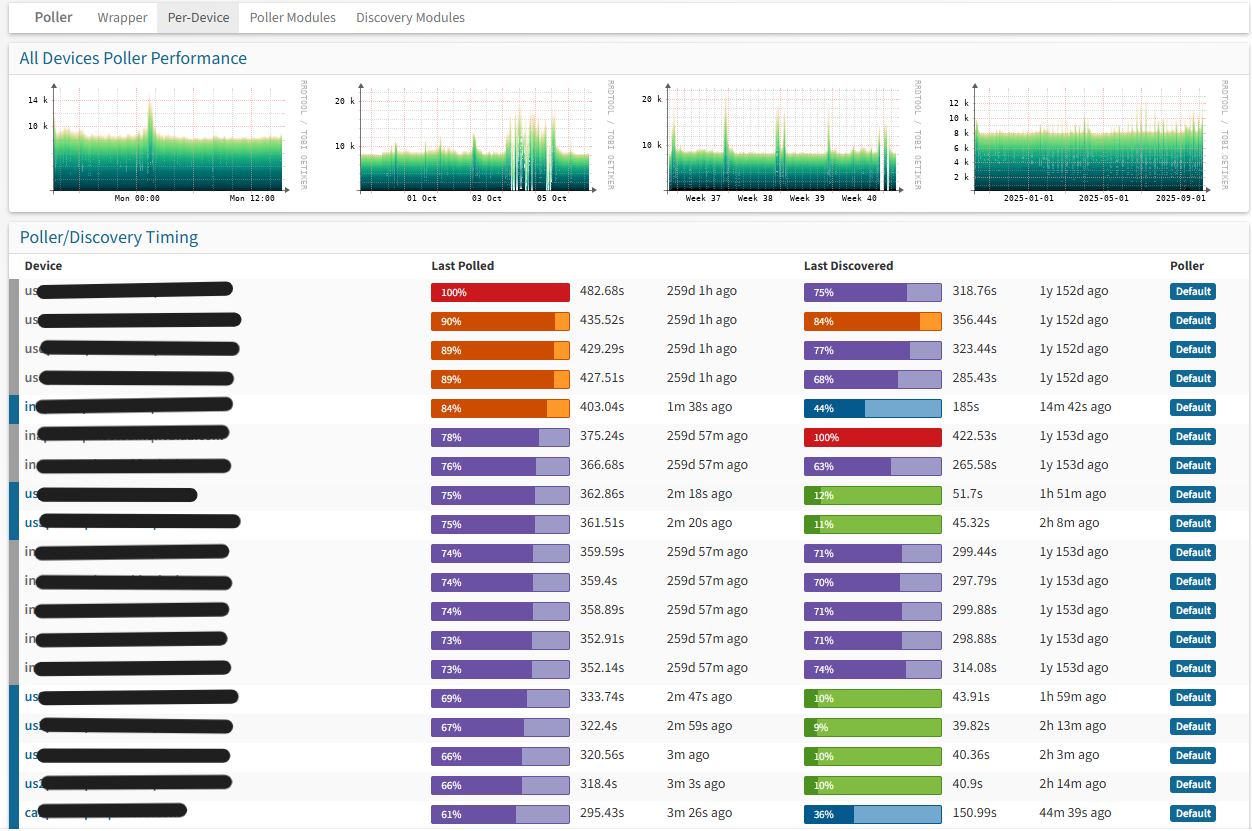
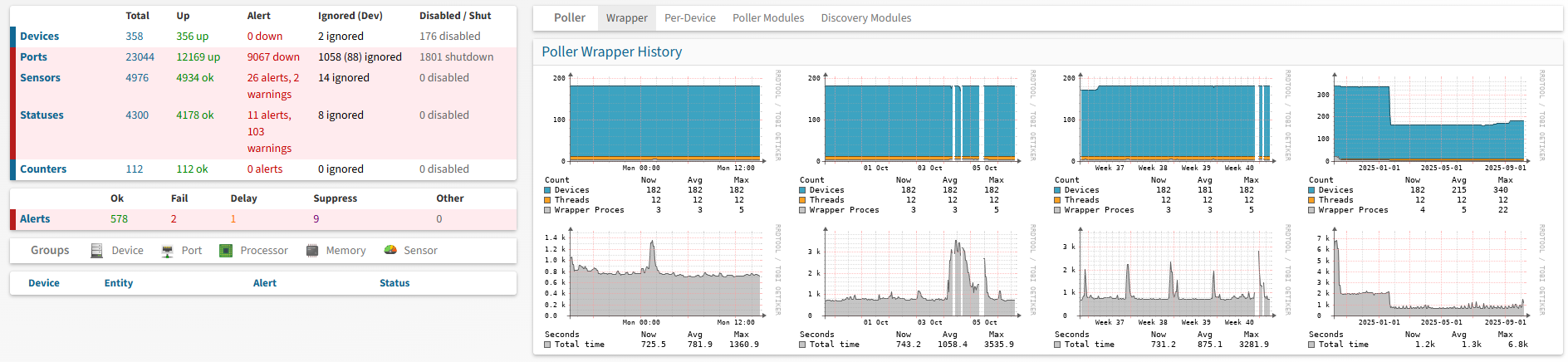
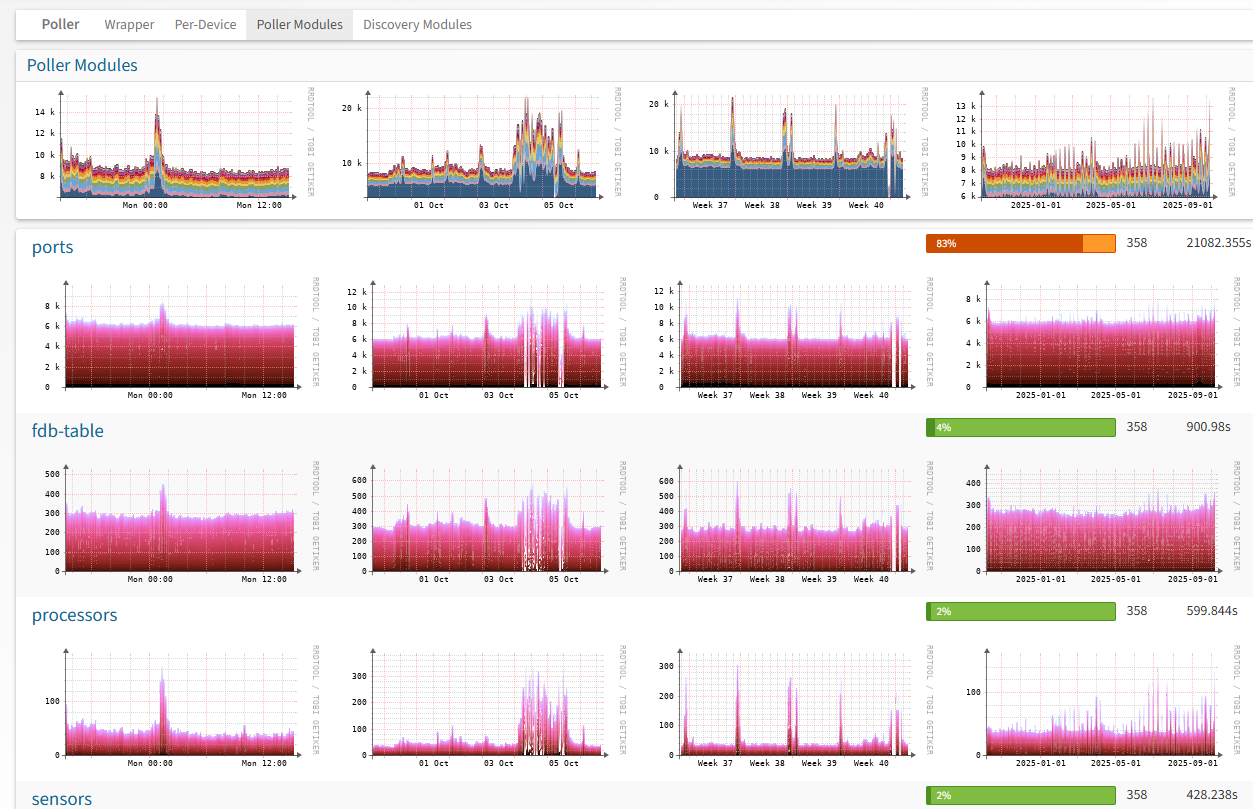
- I attached a screenshot of the "pollerlog" page. I read in the tuning section of the website that :
" Ideally, the entire Poller-wrapper process should take as close to 300 seconds as possible to ensure the lowest average load".
If I understand correctly, we have doubled that. How can we optimize this? Is it thanks to "multiple poller instances"?
4. Also, I noticed that the polling time is not good when the equipment is far from where Observium is located (FR). In this case, would it be a good idea to increase the "SNMP Maximum Repetitions"?
5. Finally, I'm not sure if this is a good idea, but we could create a poller dedicated to each country. For example, Poller 1 could monitor all hardware in India, Poller 2 could monitor all hardware in the US, Poller 3 could monitor all hardware in Canada, and Poller 4 could monitor all hardware in France.
6. In general, is it time to consider horizontal scaling? Front-end and mysql on the same VM and pollers on multiples VM.
Quick question: Is the trap still unsupported? I read an old post. I'm asking because we would like to retrieve the status of an SRX cluster, but Juniper only provides one way to do that: traps. We could use Nagios or another technology, but we would prefer to avoid using multiple monitoring technologies for our network equipment.
Thanks you.