Details
-
Bug
-
Resolution: Not A Bug
-
 Trivial
Trivial
-
None
-
Community Edition
-
None
-
virtual machine with 12 cores (Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz) and 16G of RAM running Centos7
Description
During a trial, we installed the system in a virtual machine with 12 cores (Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz) and 16G of RAM.
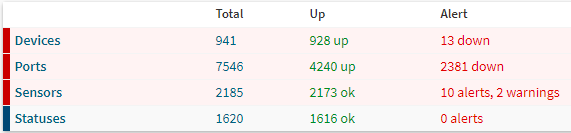
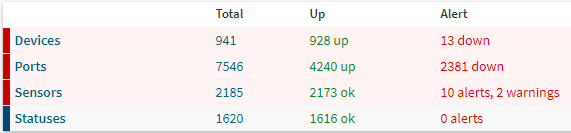
At the moment we have added the following inventory:
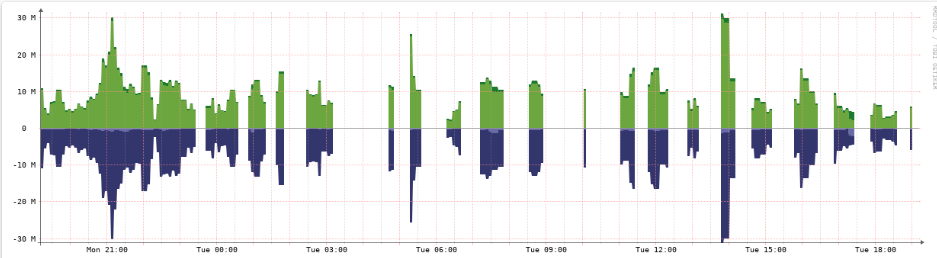
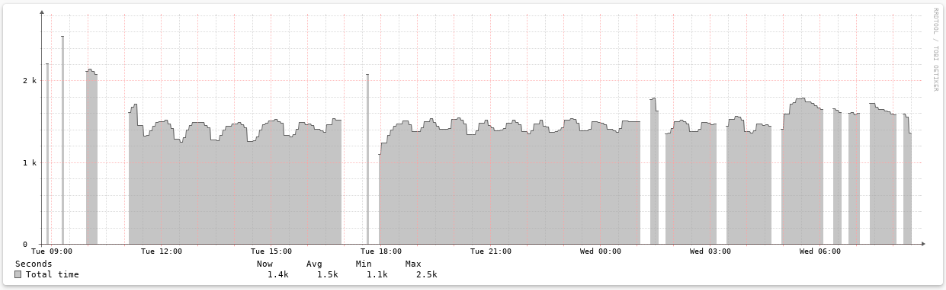
The CPU usage of the virtual machine is running at 100% so the graphs are showing lots of spaces.
Is there a recomended hardware to use?